Reinforcement Learning
Automatically determine the ideal behavior (action) within a specific situation (environment) in order to obtain optimal outcome (reward).

- Properties
- No supervisor
- Only rewards
- Importance of time
- Current input depends on previous inputs
- Delayed rewards
- Rewards may be given only after the completion of the entire task
- The agent's action affects its next input
- Performance-focesed
- Balance between exploration (of uncharted territory) & exploitation (of current knowledge)
- No supervisor
- Elements
- Agent
- Environment
- Reward
- State
- Training
- Action & policy
- Stochastic policy: $$\sum \pi(a|s) = 1$$
- Deterministic policy: $$\pi(s): S \rightarrow A$$
- Value
- Long-term rewards with discounts of the current state
- Q-value
- Long-term rewards with discounts, taking into account the current state & action
- Action & policy
Credit Assignment Problem
When the agent gets a reward, doesn't know which actions to credit or to blame.
- Discount rate
- e.g. if an agent gets rewards 10, 0, -50, and discount rate is 0.8, the score of the first action:
10 + r * 0 + r^2 * (-50)
- e.g. if an agent gets rewards 10, 0, -50, and discount rate is 0.8, the score of the first action:
Policy Gradient
Optimizes parameters of a policy by following the gradients toward higher rewards. Learns the policy function directly by maximizing rewards.
Algorithm
- At each step, compute gradients that makes the chosen action even more likely, but don't apply the gradients yet
- At the end of an episode, compute each action's score
- Multiply each gradient vector by the corresponding action's score
- Compute mean of all resulting gradient vectors, use it to perform a gradient descent step
Q-Learning
Arrive at the optimal policy through interactions with environment. Learns the state-action value function Q by minimizing temporal difference error.
repeat
select an action a
do(a)
observe reward r and state s'
Q[s, a] = Q[s, a] + alpha * (r + gamma * max_a'(Q[s', a']) - Q[s, a])
s = s'
until termination
Markov Decision Process (MDP)
- Markov chain
- A sequence of possible events
- Probability of each event depends only on the state
- Memoryless
- Markov decision process
- Add in actions & rewards

- Fundamental solutions: assume the agent knows the transition & reward probability functions, plan actions offline
- Value-iteration
- Policy-iteration
- Try policy after policy
- Q-learning solution: model-free learning environment, improves behavior through online learning
Bellman Optimality Equation
Optimal State Value
The sum of all discounted future rewards the agent can expect after reaching state $$s$$, assuming it acts optimally.
Value iteration algorithm:
$$ V^(s) = maxa \sum{s'} T(s, a, s')(R(s, a, s') + \gamma \cdot V^(s'))
$$
- $$T(s, a, s')$$: transition probability
- $$R(s, a, s')$$: reward
- $$\gamma$$: discount rate
To compute, init all $$V^*(s)$$ to 0, compute the estimated state values at each iteration:
$$ V{k+1}(s) = max_a \sum{s'} T(s, a, s')(R(s, a, s') + \gamma \cdot V_k(s'))
$$
Optimal State-Action Value (Q-Value)
The sum of all discounted future rewards the agent can expect after reaching state $$s$$ and choosing action $$a$$ but before it sees the outcome of this action, assuming it acts optimally.
Q-value iteration algorithm:
$$ Q{k+1}(s) = \sum{s'} T(s, a, s')(R(s, a, s') + \gamma \cdot max_{a'} Q_k(s', a'))
$$
Optimal policy:
$$ \pi^(s) = argmax_a Q^ (s, a)
$$
Temporal Difference Learning
Now, we don't know $$T(s, a, s')$$ and $$R(s, a, s')$$. Need to learn them:
$$ V_{k+1}(s) = (1 - \alpha)V_k(s) + \alpha(r + \gamma \cdot V_k(s'))
$$
This converges only if learning rate $$\alpha$$ gradually reduced.
Adapting Q-value iteration algorithm -> Q-learning:
$$ Q{k+1}(s, a) = (1 - \alpha)Q_k(s, a) + \alpha(r + \gamma \cdot max{a'} Q_k(s', a'))
$$
This can converge at the optimal policy if explored MDP thoroughly enough.
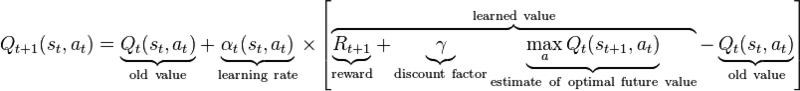
Exploitation v.s. Exploration
Finding optimal policy may take extremely long time.
- Exploitation
- Spend time at interesting parts of the environment
- Exploration
- Spend time visiting unknown regions of the MDP
ε-Greedy Policy
At each step, acts randomly with probability ε, or greedily (action with highest Q-value) with probability 1-ε. Common to start from high ε and gradually reduce it.
Bonus
Offer bonus for trying actions not tried before.
$$ Q{k+1}(s, a) = (1 - \alpha)Q_k(s, a) + \alpha(r + \gamma \cdot max{a'} f(Q_k(s', a'), N(s', a')))
$$
- $$N(s', a')$$: counts of number of times action $$a'$$ was chosen in state $$s'$$
- $$f(q, n) = q+ \frac{K}{1+n}$$: exploration function, $$K$$ is the curiosity parameter
SARSA
State-action-reward-state-action. Use current policy to choose the current & next actions, then update the Q-function.
- Off-policy learner
- Learns values of an optimal policy independently of the agent's actions
- Can learn optimal policy even if acting randomly, but might take long
- Exploitation
- e.g. Q-learning
- On-policy learner
- Learns values of the policy the agent is actually carrying out
- Exploration
- e.g. SARSA
Algorithm
select an action a using a policy based on Q
repeat
do(a)
observe reward r and state s'
select an action a' using a policy based on Q
Q[s, a] = Q[s, a] + alpha * (r + gamma * Q[s', a'] - Q[s, a])
s = s'
a = a'
until termination
- Properties
- Can find different policy than Q-learning when exploring may incur large penalties
- Will find optimal policy
Function Approximation
When state space gets large, Q-value updates can be extremely slow. Can learn a value function as a linear combination of features.
- For each state/action pair
- Determine its representation in terms of features
- Perform Q-learning update on each feature
- Q-value estimate is a weighted sum over the state/action pair's features
SARSA
Let $$F_1(s, a), \dots, F_n(s, a)$$ be the features of state $$s$$ and action $$a$$.
$$ Q_{\bar{w}}(s, a) = w_0 + w_1F_1(s, a) + \dots + w_nF_n(s, a)
$$
Algorithm
assign weights W arbitrarily
observe current state s
select an action a
repeat
do(a)
observe reward r and state s'
select an action a' using a policy based on Q_w
let delta = r + gamma * Q_w[s', a'] - Q_w[s, a]
for i = 0..n
W[i] = W[i] + eta * delta * F[s, a][i]
s = s'
a = a'
until termination
- Properties
- Reduction of size
- Feature selection/extraction non-trivial
- Learns weights for a tiny number of features
- No longer tracking values for state/action pairs
- Values estimated from features
- Weight update a form of gradient descent
- A variant of linear regression
- Restricted accuracy of learned rewards