Content
- Data Representation & Alignment
- Cache Performance
- Cache Organization
- Cache Performance Metrics
- Code Scheduling
- Blocking/Tiling
- The Memory Moutain
- Virtual Memory
- Virtual Memory Access
- Page Table & TLB
- Prefetching
- H/W Prefetching
- S/W Prefetching
- Machine-Dependent Optimizations
- Pointer Code
- Instruction-Level Parallelism
- Parallel Loop Unrolling
Data Representation & Alignment
- Primitive data type requires K bytes -> address must be multiple of K
- Structures align with the largest alignment requirement of any element
Cache Performance
- Keep working set small (temporal locality)
- Use small strides (spacial locality)
Cache Organization
address: | tag | index | offset |
cache block: | v | tag | data |
S - 2^s sets
E - 2^e blocks/lines per set
B - 2^b bytes per cache block
Cach size = S * E * B bytes
Cache Performance Metrics
- Miss rate
- Hit time
- isLineInCache? + deliver block to CPU (+virtual memory translation)
- Miss penalty
Code Scheduling
- Factors
- Reordering of loops
of read/write operations
Blocking/Tiling
- Traverse array in blocks
- Improves temporal locality
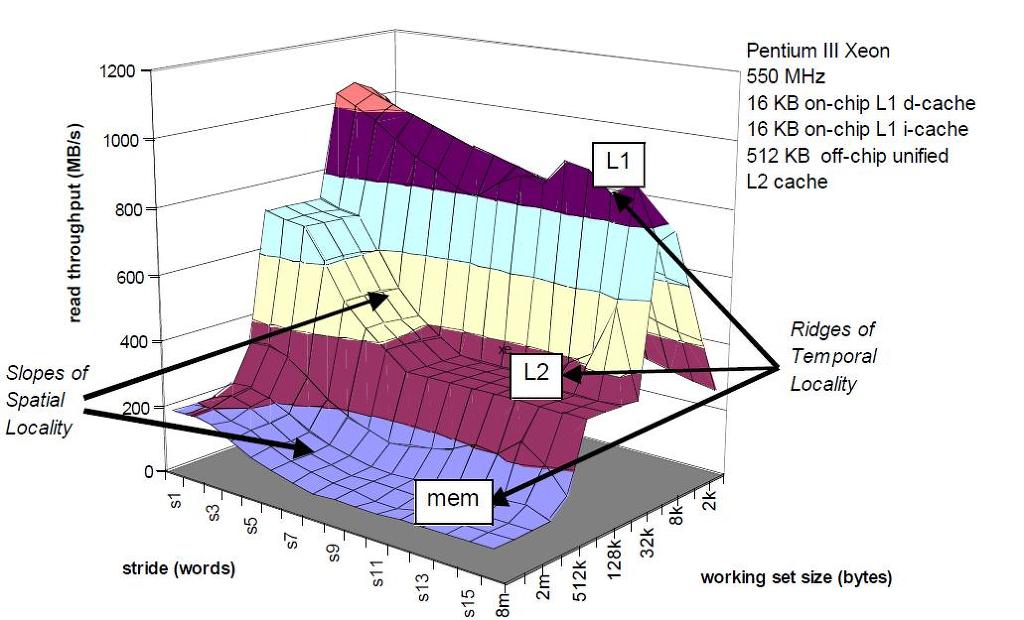
The Memory Moutain
- Measure read throughput as a function of spatial & temporal locality
Virtual Memory
- Why virtual memory?
- Capacity/Portability
- Security
- Sharing
Virtual Memory Access
- Type of cache misses
- Cold/compulsory miss
- Conflict miss
- Avoided by set-associative caches
- Capacity miss *
- Keep working set within on-chip cache capacity
- Write
- Write-back (on write-hit)
- Write-allocate (on write-miss)
- Write-through
Page Table & TLB
- MMU keep mapping of VA to PA in page table
- Page table kept in main memory, can be cached
- Translation lookaside buffer (TLB): cache for page table
- TLB hit:
CPU -> MMU -> TLB -> MMU -> Mem - TLB miss:
CPU -> MMU -> TLB -> Mem -> TLB -> MMU -> Mem - TLB reach:
(# TLB entries) * (page size)
- TLB hit:
- Working set : a set of active virtual pages
- Page miss:
(working set size) > (main mem size)-> thrashing - TLB miss:
(# working set pages) > (# TLB entries)
- Page miss:
Prefetching
- Bring into cache elements expected to be accessed in future
- Effective if:
- Spare memory bandwidth
- Accurate
- Timely
- Doesn't displace other in-use data
- Latency hidden by prefetched outweighs their cost
H/W Prefetching
- Prefetch adjacent block
- Recognize a stream: addresses separated by a stride
- Prefetch within a page boundary
S/W Prefetching
- Insert special
prefetchinstructions into code- Patterns that H/W wouldn't recognize e.g. linked list
Machine-Dependent Optimizations
Pointer Code
- Not necessarily better than array code; some compilers do better job optimizing array code
Instruction-Level Parallelism
- Limiting factor
- Latency of instructions
- Number of functional units available
- 1 load
- 1 store
- 2 int (1 may be branch)
- 1 FP add
- 1 FP mul/div
Parallel Loop Unrolling
- Accumulate in 2 different products, combine at end
(1 * x2 * ... * xn) * (1 * x1 * ... * x_n-1)
Dual product
(1 * x1) * (x2 * x3) * ... * (x_n-1 * xn)
Limitations
- Need lots of registers to hold sums/products